
在多目摄像头中往往存在多个成像器件,如图1所示。

图1 多目深度摄像头
这些摄像头由于位置、成像参数之间存在差异,导致其视角并不相同,如图2所示。通过视角的差异,可以像人眼一样估算空间点到相机的距离。

图2 红外IR和彩色RGB相机视角差异
如果直接将两个摄像头的画面进行叠加,会出现画面中元素错位的情况。这种错位将会为后续图像的识别带来麻烦,因此需要将两个或多个摄像头的图像进行对齐矫正,而后再叠加处理。
1 基本原理
多目摄像机在生产时,镜头的安装存在一定的误差,导致两个摄像头的成像面并不重叠,存在一定的偏转,如图3所示。
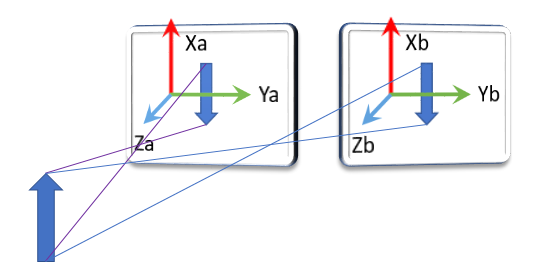
图3 双面摄像机成像示意图
在图3中双目摄像机中的两个摄像头虽然成像面存在一定的偏差,但是所拍摄画面中的元素基本相同。 设A传感器的成像面可用坐标系Xa、Ya、Za描述;B传感器的成像面可用Xb、Yb、Zb描述。则同一个物体在两个成像面中形成的像素可以用两个不同的坐标系描述。因此必然存在一个有A成像面坐标系到B成像面坐标系的变换。因此,可以通过在画面中寻找多个相同坐标点,并计算出相应的变换矩阵。相关基本原理在摄像头标定中已阐述。
2 基于opencv的双目摄像头标定
在双目摄像头的标定中依旧使用张正友棋盘标定格(12×9),如图4所示。

图4 张正友棋盘标定板(12×9)
首先获取两个摄像头拍摄同一标定板的照片,如图5所示。为了后续处理简单,此时应将两幅画面的尺寸统一。

图5 双目相机画面
rgb_img2 = cv2.resize(cv2.imread(f"./img/61.bmp"), (320, 240), interpolation=cv2.INTER_NEAREST)
ir_img2 = cv2.imread(f"./img/62.bmp")而后应分别在两幅画面中寻找出对应的特征点。
def find_chessboard(self, img, pattern=(9, 8), wind_name="rgb", show_en=False):
# read input image
# img = cv2.imread(filename)
# cv2.imshow("raw", img)
# img = cv2.undistort(img, camera_matrix, distortion_coefficients)
# convert the input image to a grayscale
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# Find the chess board corners
ret, corners = cv2.findChessboardCorners(gray, pattern, None)
# if chessboard corners are detected
if ret == True:
# Draw and display the corners
if show_en:
img = cv2.drawChessboardCorners(img.copy(), pattern, corners, ret)
# Draw number,打印角点编号,便于确定对应点
corners = np.ceil(corners[:, 0, :])
if show_en:
for i, pt in enumerate(corners):
cv2.putText(img, str(i), (int(pt[0]), int(pt[1])), cv2.FONT_HERSHEY_COMPLEX, 0.3, (0, 255, 0), 1)
cv2.imshow(wind_name, img)
return corners
return Noneimg1_corners = self.find_chessboard(img1, chessboard_param, "img1", show_en)
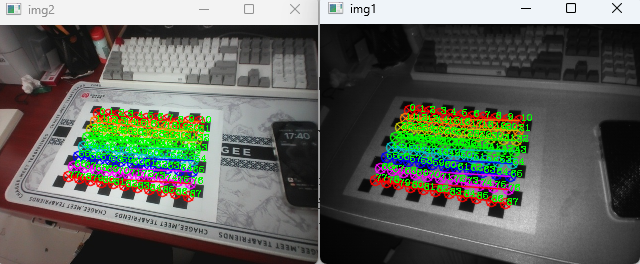
img2_corners = self.find_chessboard(img2, chessboard_param, "img2", show_en)运行结果如图6所示。图7为索引号为1的特征点。
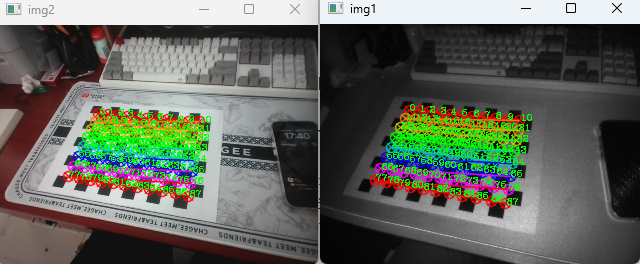
图6 棋盘格特征点寻找
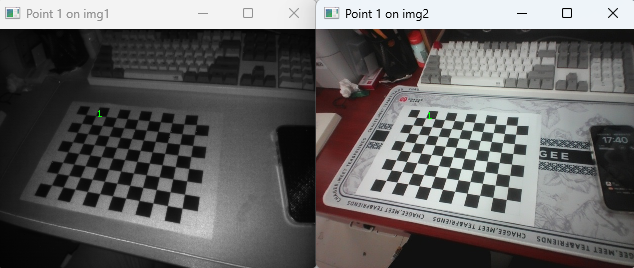
图7 单个特征点对比
获取到所有特征点后,则应通过对应的特征点计算变换矩阵。可通过cv2的findHomography函数实现。
H,S=cv2.findHomography(srcPoints,dstPoints,Threshold,mask,maxIters,confidence)| 参数 | 解释 |
|---|---|
| srcPoints | 目标中的特征点 |
| dstPoints | 与目标图片相匹配的特征点 |
| method | 计算单应矩阵所使用的方法,不同的方法对应不同的参数,具体如下: 0 – 利用所有点的常规方法,RANSAC – RANSAC-基于RANSAC的鲁棒算法,LMEDS – 最小中值鲁棒算法,RHO – PROSAC-基于PROSAC的鲁棒算法 |
| Threshold | 若srcPoints和dstPoints是以像素为单位的,则该参数通常设置在1到10的范围内 |
| mask | 可选输出掩码矩阵,通常由鲁棒算法(RANSAC或LMEDS)设置。 请注意,输入掩码矩阵是不需要设置的 |
| maxIters | RANSAC算法的最大迭代次数,默认值为2000 |
| confidence | 可信度值,取值范围为0到1. |
其返回值有两个,一个是变换矩阵H,另一个是status向量,用来删除错误的匹配。
src_pts = []
for img_idx in range(len(img1_corners)):
src_pts.append(img2_corners[img_idx])
h, status = cv2.findHomography(np.array(src_pts)[:, None, :], img1_corners[:, None, :])在获取变换矩阵后则可继续完成画面对齐,即将B的画面映射到A的成像面上去。这一步通过cv2.warpPerspective实现透视变换。
cv2.warpPerspective函数是OpenCV库中用于执行透视变换的函数之一。它可以将图像从一个透视投影转换为另一个透视投影,实现图像的旋转、缩放、平移等操作。该操作可表示为:
DST = M * SRC
上式中SRC表示原图像,DST表示变换后图像,M表示透视变换矩阵(3×3)。 该函数参数如下
| 参数 | 说明 |
|---|---|
| src | 源图像,即待进行透视变换的图像。 |
| M | 变换矩阵,即3×3的透视变换矩阵。 |
| dsize | 目标图像的大小,以元组形式表示,例如(width, height)。 |
| flags | 插值方法的标志,用于指定插值方法,默认为cv2.INTER_LINEAR。 |
| borderMode | 边界模式,用于指定超出边界的像素处理方式,默认为cv2.BORDER_CONSTANT。 |
| borderValue | 当边界模式为cv2.BORDER_CONSTANT时,用于指定边界像素的值,默认为0。 |
返回值 目标图像,即经过透视变换后的图像。
通过下面的程序进行叠加画面。
img2_warp = cv2.warpPerspective(img2, self.H, (img2_w, img2_h), borderValue=(255, 255, 255))
img1_height, img1_width = img1.shape[:2]
img2_warp_sized = cv2.resize(img2_warp, (img1_width, img1_height), cv2.INTER_AREA)
merge = cv2.addWeighted(img1, alpha, img2_warp_sized, 1 - alpha, gamma=0)运行结果如图8所示。

图8 画面矫正及叠加结果
由于两个摄像头之间的相对位置关系在出厂后正常情况下基本固定。因此,变换矩阵可不必经常更新。如果摄像头经过了严重的磕碰,有可能导致相对位置出现变动,此时应重新标定校准。如图9为处理实时视频流的效果。

图9 变换矩阵实时融合双目画面